AI 도입했는데 왜 아무도 안 쓸까
기업 74%가 AI 투자에서 ROI를 못 거둡니다. 모델이 멍청해서가 아닙니다. 빠진 건 조직의 지식입니다.

윤성열
프렌티스 대표이사, 공학박사
2026년 3월 20일
AI 도입했는데, 왜 아무도 안 쓸까
기업에서 AI 도입 컨설팅을 하다 보면, 가장 자주 듣는 말이 있습니다.
“처음엔 신기해서 다들 썼는데, 두세 달 지나니까 아무도 안 써요.”
대표나 팀장은 답답합니다. 라이선스 비용도 내고, AI 교육도 시켰는데 왜 직원들이 안 쓰는지 모르겠다고 합니다. 반대편에서 직원들한테 물어보면 이유는 명확합니다.
“우리 회사 맥락을 모르니까, 결과물을 다 고쳐야 해요. 차라리 내가 쓰는 게 빨라요.”
위에서는 “왜 안 쓰지?”, 아래에서는 “써봤는데 안 돼.” 도구의 문제가 아니라, 도구와 조직 사이에 뭔가가 빠져 있다는 뜻입니다.
숫자가 말해주는 것
이건 우리나라만의 현상이 아닙니다.
BCG가 59개국 CxO 1,000명을 대상으로 조사한 결과, 기업의 74%가 AI 투자에서 실질적 가치를 달성하지 못하고 있다 고 답했습니다.1 MIT NANDA Initiative의 후속 연구는 더 극단적입니다. 생성형 AI 파일럿의 95%가 측정 가능한 매출 성장을 만들어내지 못했습니다.2
Gartner는 2025년 말까지 생성형 AI 프로젝트의 30%가 PoC 이후 폐기될 것 이라 예측했습니다. 이유로 데이터 품질, 비용 상승, 비즈니스 가치 불명확을 꼽았습니다.3
한국도 마찬가지입니다. 대한상공회의소 조사에서 국내 기업의 78.4%가 AI가 필요하다고 답했지만, 실제 활용률은 30.6% 에 그칩니다. 중소기업은 28.7%로 더 낮습니다.4
GPT-5.4, Claude Sonnet 4.6, Gemini 3.1 Pro — 모델은 이미 충분히 똑똑합니다. 모델에 문제가 있다면 이렇게 일관된 패턴이 나올 수 없습니다. 그러면 뭐가 빠진 걸까요?
회사의 지식이라는 것
회사에는 두 종류의 지식이 있습니다.
하나는 눈에 보이는 지식입니다. 매뉴얼, 업무 가이드, 위키, SOP 같은 것들. 문서로 정리되어 있고, 누구나 찾아볼 수 있습니다. 지식경영에서는 이걸 명시지(Explicit Knowledge) 라고 부릅니다.
다른 하나는 눈에 보이지 않는 지식입니다. “이 고객사는 가격보다 일정을 중요시한다”는 영업 감각. “이 API는 문서에는 안 나오지만 이렇게 써야 안정적이다”는 개발 노하우. “이 용어는 우리 회사에서 다른 의미로 쓴다”는 조직 맥락. 이런 것들은 문서에 적혀 있지 않습니다. 사람의 머릿속에, 경험 속에 있습니다. 암묵지(Tacit Knowledge) 라고 합니다.
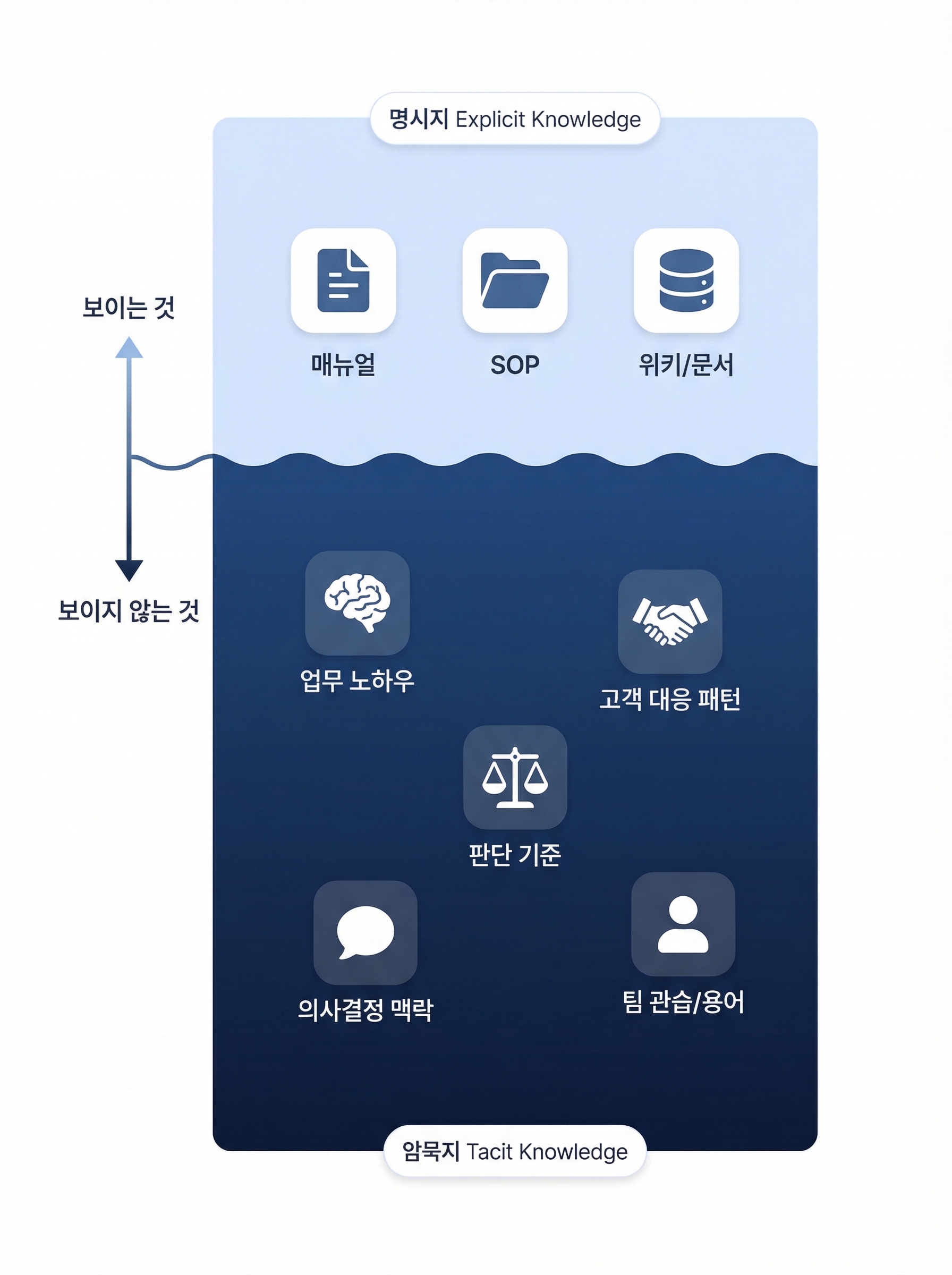
빙산 그림을 떠올리면 이해가 쉽습니다. 수면 위로 보이는 부분은 작습니다. 진짜 덩어리는 물 아래에 있습니다. 회사의 지식도 마찬가지입니다. 문서화된 것은 일부이고, 실제로 업무를 돌아가게 만드는 것은 사람들의 머릿속에 있는 암묵지입니다.
신입사원이 적응하는 데 3~6개월이 걸리는 이유가 바로 이겁니다. 매뉴얼은 일주일이면 읽을 수 있지만, 조직의 암묵지를 체득하는 데는 몇 달이 필요합니다.
AI는 빙산의 윗부분만 본다
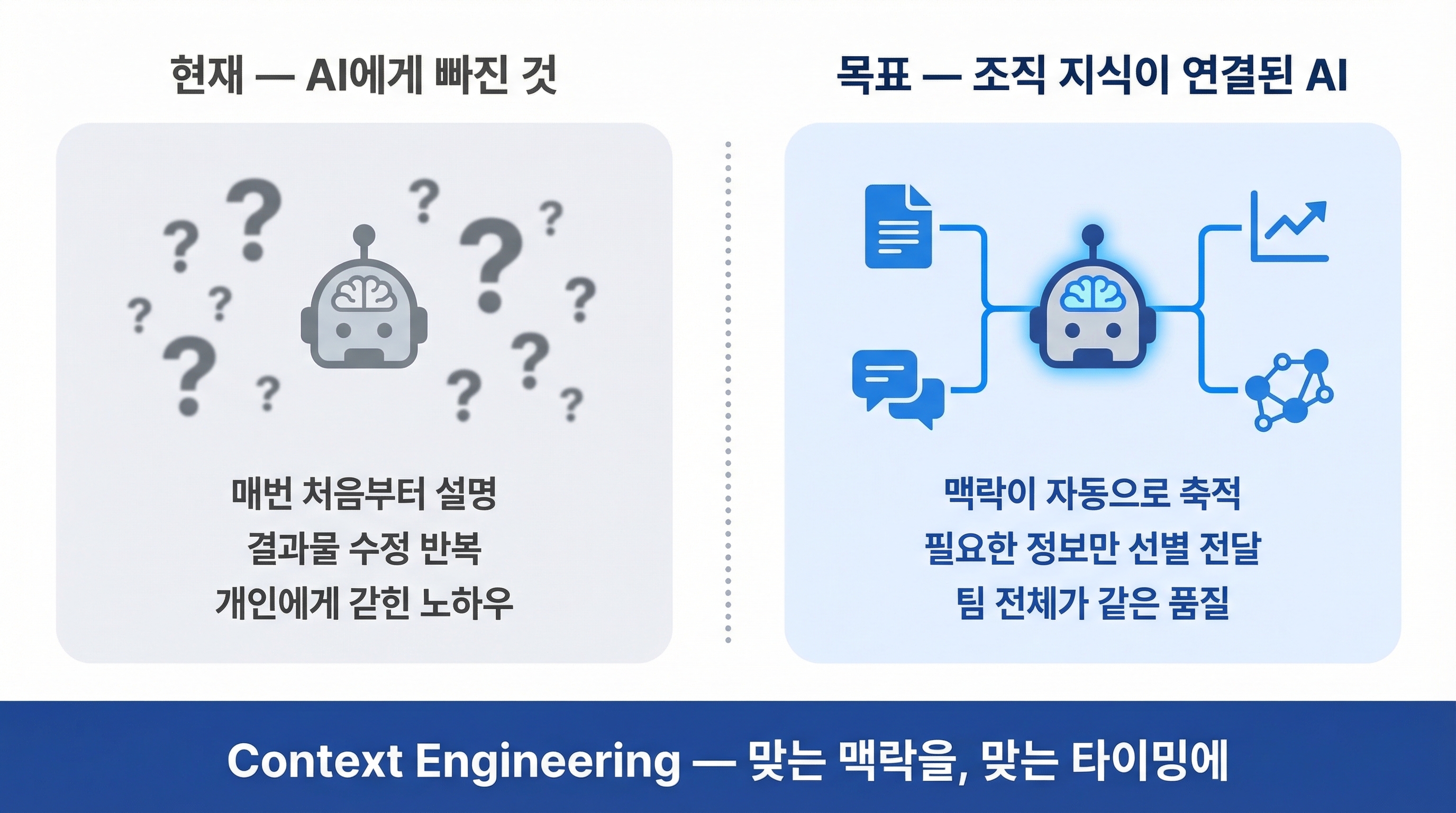
여기서 문제가 생깁니다. AI는 우리가 넣어주는 정보만 봅니다. 그리고 우리가 넣어줄 수 있는 건 대부분 명시지 — 문서, 데이터, 매뉴얼 — 뿐입니다.
빙산의 아랫부분, 그러니까 실제로 업무 품질을 결정하는 암묵지는 AI에게 전달되지 않습니다. 대화창을 열 때마다 AI는 리셋됩니다. 어제 나눈 대화의 맥락도, 지난달 프로젝트에서 배운 교훈도, 우리 회사만의 용어도 — 매번 처음부터 다시 설명해야 합니다.
현장에서 이게 어떻게 나타나는지 하나만 보겠습니다.
영업팀 김 과장이 고객사 A의 특성을 프롬프트에 잘 정리해서 괜찮은 제안서 초안을 뽑았습니다. “이 고객은 비용보다 기술 안정성을 중시한다”, “전에 B사에서 옮겨온 담당자라 B사 사례는 피해야 한다” 같은, 경험에서 나온 정보를 녹인 겁니다. 결과는 좋았습니다.
그런데 그 프롬프트는 김 과장의 노트 어딘가에 있습니다. 다음 달, 다른 직원이 같은 고객사를 대응할 때는 처음부터 다시 시작합니다. 김 과장이 쌓은 맥락은 조직의 자산이 되지 못합니다.
이런 일이 반복되면, 팀에서 프롬프트를 잘 짜는 한 사람이 “AI 담당”이 됩니다. 그 사람이 바빠지거나 퇴사하면, 팀의 AI 활용도는 바닥으로 떨어집니다.
McKinsey의 2025년 State of AI 보고서도 같은 지점을 짚습니다. GenAI를 도입한 기업의 72%가 최소 한 개 기능에서 활용하고 있지만, 기업 전사 수준에서 실질적 이익을 보고한 비율은 39%에 불과 합니다.5 개인의 생산성은 올라가도 조직의 생산성은 제자리인 상태. 암묵지가 공유되지 않으니 당연한 결과입니다.
”문서를 다 넣으면 되지 않나?”
자연스럽게 이런 질문이 나옵니다. RAG(Retrieval-Augmented Generation) — 쉽게 말해, 회사 문서를 검색 가능한 저장소에 넣어두고, AI가 질문을 받으면 관련 문서를 찾아서 함께 읽는 방식입니다. 실제로 많은 기업이 이걸 시도하고 있고, 잘 설계하면 효과도 있습니다.
그런데 RAG만으로는 부족한 지점이 있습니다.
첫째, 대부분의 RAG 시스템은 이미 문서화된 명시지를 대상으로 합니다. 물론 Slack 대화, 회의록, 고객 통화 녹취 같은 비정형 데이터를 넣으려는 시도도 있지만, 진짜 중요한 암묵지 — 사람의 머릿속에 있는 판단 기준과 노하우 — 는 여전히 포착하기 어렵습니다.
둘째, 많이 넣는다고 좋아지지 않습니다. 2024년 arXiv에 발표된 연구에 따르면, 당시 평가된 LLM 중 64,000 토큰 이상의 긴 컨텍스트에서 일관된 정확도를 유지하는 모델은 소수에 불과했습니다.6 모델의 성능은 빠르게 개선되고 있지만, 관련 없는 정보가 많아지면 정확도가 떨어지는 근본적인 문제는 여전합니다.
결국 RAG는 중요한 기반 기술이지만, 그것만으로는 충분하지 않습니다. 맞는 정보를, 맞는 타이밍에, 맞는 형태로 전달하는 구조 가 필요합니다.
컨텍스트 엔지니어링이라는 답
2025년 중반, 이 문제를 정면으로 다루는 개념이 업계에서 주목받기 시작했습니다. 컨텍스트 엔지니어링(Context Engineering) 입니다.
Shopify CEO Tobi Lütke가 이 용어를 대중적으로 확산시켰고, OpenAI 공동 창업자 Andrej Karpathy가 강하게 동의했습니다.
“사람들은 프롬프트를 짧은 지시문 정도로 생각합니다. 하지만 실전에서 중요한 건 컨텍스트 엔지니어링 — 컨텍스트 윈도우에 딱 맞는 정보를 채워넣는 섬세한 기술 입니다.” — Andrej Karpathy7
프롬프트 엔지니어링이 “어떻게 질문할 것인가”에 집중했다면, 컨텍스트 엔지니어링은 그 범위를 확장해 “AI에게 무엇을 보여줄 것인가” 까지 다룹니다. RAG도, 시스템 프롬프트 설계도, 메모리 구조 설계도 모두 컨텍스트 엔지니어링의 일부입니다. 그리고 이 “무엇”에는 명시지뿐 아니라, 조직의 암묵지까지 포함되어야 합니다.
Frontiers in Artificial Intelligence에 발표된 체계적 문헌 리뷰도 이 방향을 지지합니다. AI가 조직의 지식 발견, 수집, 저장, 공유를 강화할 수 있지만, 데이터 품질, 직원 저항, 기존 워크플로와의 정렬 이 3대 장벽이라고 분석합니다.8 기술만으로는 안 되고, 기술과 조직 지식 구조를 함께 설계해야 한다는 뜻입니다.
그래서, 어떻게 풀 수 있을까
결국 필요한 건 이런 시스템입니다. 업무 중 발생하는 암묵지를 자동으로 포착하고, 축적하고, AI가 필요로 할 때 맞는 맥락만 골라서 전달하는 구조. 누군가 일일이 정리하지 않아도, 일하는 과정 자체에서 조직의 지식이 쌓이는 시스템. 이게 만들어지면, 김 과장이 퇴사해도 그가 쌓은 맥락은 남습니다.
쉽지 않은 문제입니다. 모델이 바뀌어도, 도구가 바뀌어도, 조직의 지식을 AI에 연결하는 구조 가 없으면 같은 벽에 부딪히는 걸 현장에서 반복적으로 봐왔습니다. 그래서 프렌티스는 이 문제를 시스템으로 풀어보기 위해 R&D 과제를 제안했고, 중소벤처기업부 창업성장기술개발사업(디딤돌)에 선정되어 18개월간 본격적으로 연구를 진행하게 됐습니다.
이 프로젝트를 진행하면서 부딪히는 기술적 문제들 — 어떤 지식을 자동으로 포착할 것인가, 맥락의 관련성을 어떻게 판단할 것인가, 개인의 암묵지를 조직의 명시지로 전환하는 게 실제로 가능한가 — 을 하나씩 풀어보려고 합니다.
다음 글의 주제는 아마 “맥락 축적을 시도했다가 실패한 첫 번째 경험” 이 될 것 같습니다. 성공 사례보다 실패에서 배우는 게 더 많으니까요.
참고 자료
Footnotes
-
BCG. (2024). “Where’s the Value in AI?” 59개국 CxO 1,000명 대상 조사. PR Newswire ↩
-
Challapally, A. et al. (2025). “The GenAI Divide: State of AI in Business 2025.” MIT NANDA Initiative. Fortune 보도 ↩
-
Gartner. (2024). “Gartner Predicts 30% of Generative AI Projects Will Be Abandoned After Proof of Concept By End of 2025.” THE Journal 보도 ↩
-
대한상공회의소·산업연구원. (2024). “국내 기업 AI 기술 활용 실태 조사.” 500개 기업 대상. 보고서 원문 ↩
-
McKinsey & Company. (2025). “The State of AI: How Organizations Are Rewiring to Capture Value.” 105개국 1,993명 응답. 보고서 원문 ↩
-
Leng, Q. et al. (2024). “Long Context RAG Performance of Large Language Models.” arXiv:2411.03538. 논문 원문 ↩
-
Gelashvili-Luik, T. et al. (2025). “Navigating the AI revolution: challenges and opportunities for integrating emerging technologies into knowledge management systems.” Frontiers in Artificial Intelligence. 논문 원문 ↩